Disclaimer: questo post contiene spoiler di Strappare lungo i bordi, la serie animata per Netflix creata, scritta e diretta da Zerocalcare.
C’è stata una cosa che ho apprezzato molto della serie di Zerocalcare: la parola “anche”.
Continua a leggere
Disclaimer: questo post contiene spoiler di Strappare lungo i bordi, la serie animata per Netflix creata, scritta e diretta da Zerocalcare.
C’è stata una cosa che ho apprezzato molto della serie di Zerocalcare: la parola “anche”.
Continua a leggereEva 3+1 l’ho visto ad agosto, diciamo nelle 48 ore dopo dalla pubblicazione in Italia. Per l’occasione mi sono fatto la maratona della “Nuova versione cinematografica” in due giorni, come mi ero riproposto quando uscì il terzo capitolo («ho capito, tocca vederseli tutti d’un fiato, altrimenti non se ne esce vivi», e poi ci sono voluti 10 anni perché uscisse l’ultimo capitolo, mortacci tua Anno).
Perché ne parlo adesso? Perché finalmente un amico s’è degnato di finire la quadrilogia (ciao Lù <3 ). Ma anche perché oggi mi va di parlarne.
Di cosa sto parlando? Di come si sta dopo che hai chiuso un capitolo della tua vita e guardi avanti.
Ci sono spoiler? Sì, di NGE e pure di BoJack Horseman. Vale come avviso.
Continua a leggereLiberamente ispirata da Phastidio e Fanelli.
Il libero mercato è un modo per allocare le risorse in modo efficiente. Efficiente, però, non significa giusto.
La democrazia è un modo per allocare le risorse in modo giusto. Giusto, però, non significa efficiente.
La dialettica fra queste due forze è ciò che regge in piedi entrambe, come un pendolo che oscilla ora a un estremo, ora all’altro.
La differenza la fa la priorità che la società assegna ai problemi. Là dove la maggioranza decide che bisogna puntare, là punta il pendolo.
Questa società ha perso il senso delle priorità comuni e punta solo alle priorità individuali. Quindi, è solo normale che il potere oggi sia in mano a persone che puntano alla propria priorità, ossia prendere il potere.
Per farci cosa, si vedrà una volta preso. Intanto, lo prendono.
E chi li vota compie un transfert nella persona che hanno eletto ha preso il potere, pensando così che abbiano assunto loro il potere.
Questa, nel frattempo, non è una soluzione né efficiente, né giusta.
Finirà come con il monologo di Gaber sul suicidio: «C’è una fine per tutto. E non è detto che sia sempre la morte».
Disclaimer: questo post è stato aggiornato il 26 luglio 2019, per includere delle cose su cui ho ricevuto risposta nel frattempo.
Da qualche tempo, mi sto dilettando a sperimentare con il modulo Sports table e i relativi sotto-moduli. Ne sono rimasto affascinato perché la grafica è migliore — di svariati ordini di grandezza — delle tabelle standard che ci siamo inventati noi su it.wikipedia, non foss’altro che le uniforma tutte allo standard wikitable e permette di abbandonare quelle arlecchinate che si sono solidificate nel tempo (per esempio, queste).
Non si tratta di un modulo perfetto, tant’è vero che ho anche suggerito varie correzioni, ma va anche riconosciuto che è davvero difficile tenere conto delle migliaia di piccole cose che variano da sport a sport e da torneo a torneo. Questo non significa che sia un fallimento, devi semplicemente segnarti le cose che non vanno, in modo da sistemarle o farle sistemare mano a mano (certo, poi devi ricordare i principi di questa logica anche ai wikipediani, ma questa è un’altra storia).
Come succede ogni singola, dannatissima volta, le mie sperimentazioni diventano riflessioni sui massimi sistemi e, soprattutto, su come rendere il lavoro il meno pesante e il più riutilizzabile possibile. Ecco qua le riflessioni di questa volta.
Partiamo proprio dalle basi e dai problemi più evidenti: i moduli Sports table restano qualcosa che va compilato in locale. Peggio ancora: sono una struttura bruta che poi va, eventualmente, importata all’interno di un template. Su en.wikipedia hanno “risolto” il problema facendo un template per ogni incontro e ogni classifica — cosa che su it.wikipedia non è (giustamente) proponibile nemmeno per errore. Il mio tentativo di creare dei template base che integrassero i moduli è andato male, ma c’è anche da dire che io di Lua non ne capisco granché.
Poi c’è il problema di ripulire i risultati, cioè inserire i vari Incontro internazionale o Incontro di club per permettere una visualizzazione più decente dei risultati stessi (e qua c’è il problema delle decine di migliaia di template bandierina che abbiamo), senza contare che di template per la gestione di risultati, classifiche e quant’altro c’è solo l’imbarazzo della scelta (e sto parlando solo di it.wikipedia, replicate il discorso per tutti gli altri progetti…).
In tutto questo, si rischia di perdere d’occhio l’ovvio, ossia che i risultati di una competizione sportiva sono uguali per tutte le versioni di Wikipedia. Già questo dovrebbe far riflettere sull’opportunità di centralizzare questi dati da qualche parte, in modo da poterli strutturare in modo efficiente e richiamarli all’occorrenza, tanto più che un data model c’è e funziona ragionevolmente. Ma come? E dove?
Partiamo dal dove. A naso il candidato migliore per ospitare tutti questi dati sembrerebbe essere Wikidata, ma l’apparenza inganna: è il posto migliore per ospitare una parte dei dati, ma non la loro totalità. Il perché si capisce vedendo il data model che ho realizzato anni fa: ciascun torneo va suddiviso in fasi, a loro volta da suddividere in giornate, a loro volta da suddividere in singoli incontri (e questo quando le cose vanno bene).
Facciamo l’esempio dell’edizione in corso della Serie A. Il campionato si suddivide in 38 giornate da 10 incontri l’una, quindi bisogna considerare nell’ordine:
Insomma, ridendo e scherzando, parliamo di 419 elementi che dovrebbero essere importati/creati in Wikidata. Moltiplicate quindi tutto questo per tutte le edizioni della Serie A (la cui formula è variata nel tempo, assieme al numero di squadre partecipanti), poi aggiungeteci le prime divisioni di tutti i campionati del mondo di calcio, poi aggiungeteci le coppe e i campionati continentali, mondiali e olimpici di calcio, poi fate lo stesso ragionamento per tutti gli sport… e poi domandatevi fin dove possiamo spingerci con le seconde, terze e quarte (e magari quinte, seste, settime…) divisioni, con i tornei amichevoli estivi, con le competizioni per selezioni di Stati non riconosciuti e così via. Ah, e non mettetevi a fare l’errore di pensare poi agli elementi riguardanti i giocatori, gli impianti, gli allenatori, gli arbitri e giudici di gara, eccetera, eccetera.
E questo, ripeto, è un caso semplice. Prendiamo in considerazione, come caso difficile, la Prima divisione CCI 1921-1922, dove abbiamo la seguente struttura:
Qui il problema non è tanto il numero di elementi totali (570), quanto il numero di elementi da dedicare soltanto alla struttura del campionato (108, poco meno di un quinto del totale), senza contare il mal di testa atroce che viene a incastrare tutte le occorrenze. E nemmeno mi avvicino alla Coppa Italia 1922, che è un altro ottimo esempio di come possa diventare estremamente difficile gestire queste cose (una rappresentazione grafica di quel delirio è qui).
Ricordiamoci pure un’altra cosa: il 99% degli incontri non sono come i Superbowl, le finali della Coppa del mondo di calcio o quei singoli incontri che, per un motivo o l’altro, hanno fatto la storia (come la “partita del secolo”, il “miracolo sul ghiaccio” o il “bagno di sangue di Melbourne”). In altri termini, il 99% degli incontri non ha diritto a una voce dedicata e, quindi, a un elemento su Wikidata dedicato. Eppure, questi dati da qualche parte vanno messi.
La soluzione che ho trovato è, molto semplicemente, quella di separare quello che può andare su Wikidata da quello che non ci deve andare. In altri termini:
Con una Wikibase autonoma, si possono creare tutti gli elementi che vogliamo e inserirvi tutti i dati che vogliamo, dal semplice risultato fino alla formazione completa, dettagliata fino al numero di maglia, alle sostituzioni e ai cartellini. Per evitare, però, duplicazioni di dati fra Wikidata e Wikisports, tutto quello che possiamo evitare di importare da Wikidata o di ospitare su Wikisports dovrebbe funzionare tramite federazione.
Riprendiamo l’esempio della Serie A e ipotizziamo un Milan-Napoli che si tiene allo stadio “Giuseppe Meazza” di Milano. Qui abbiamo almeno quattro entità (la squadra di casa, la squadra ospite, lo stadio e la città in cui si tiene la partita) che hanno, per motivi comprensibili, un elemento dedicato su Wikidata. Dal momento che sarebbe stupido ricopiare/duplicare i dati di queste quattro entità da Wikidata a Wikisports, è più logico richiamare direttamente gli elementi appositi in un modo molto simile a quello che avviene (o meglio, inizia ad avvenire) tramite Structured Data.
Lo stesso ragionamento va fatto anche per i giocatori, gli allenatori, gli arbitri e i giudici di gara, eccetera (certo, non è il massimo della vita avere migliaia di elementi su giocatori dilettanti, di cui magari a stento conosciamo il nome completo, ma per il momento non è possibile fare di meglio). In questo modo, su Wikisports resterebbero soltanto i (pochi) dati che ci interessa mantenere lì dentro, come per esempio l’orario e la data della partita oppure la giornata di riferimento. [Nota: questo paragrafo e quello precedente sono stati rivisti e aggiornati il 26 luglio 2019]
Sempre ragionando in termini molto ampi, avremmo:
In questo senso, la soluzione di en.wikipedia (quella di creare un template per ogni singola classifica e incontro) potrebbe essere pure adottata senza grossi problemi, dal momento che a ogni singolo template corrisponderebbe un elemento su Wikisports.
Questo potrebbe significare quindi:
Ovviamente, ci sono una serie di problemi. Il primo fra tutti è che, prima di vedere moduli e template globali, passerà tanto, tanto tempo. Poi, c’è il problema del capire come fare i moduli, come strutturare i template, come strutturare la grafica, come richiamarli all’interno delle voci, se e come sarà gestibile un tale scambio di dati, ma soprattutto la fatica immane di creare gli elementi su Wikisports e su Wikidata che mancano.
Tuttavia, «it’s fun to dream» (cit.).
Disclaimer: questo post è stato realizzato come prova per un colloquio di lavoro che ho fatto qualche mese fa e che, purtroppo, non si è concluso bene. Arrivati a questo punto, lo pubblico, casomai possa interessare a qualcuno.
La base della ricerca è composta dai rapporti 2014, 2015, 2016 e 2017 del Ministero dell’Interno sui provvedimenti di commissariamento degli Enti locali, in un periodo che va dal 1º gennaio 2013 al 31 dicembre 2016. Si chiarisce che i dati qui analizzati si riferiscono soltanto ai comuni, essendo stati esclusi dalla ricerca sia le province, sia gli altri enti inclusi dal Ministero nei suoi rapporti.
I dati principali sono stati poi integrati con quelli provenienti dal sito UrbanIndex, a cura del Dipartimento per la programmazione e il coordinamento della politica economica della Presidenza del Consiglio dei ministri.
Il dataset completo, con i relativi file di accompagnamento, è disponibile a questo link.
Le ragioni per cui un comune può essere commissariato sono espressamente indicate all’articolo 141 del Testo unico degli Enti locali (TUEL). Fra le principali ragioni, troviamo:
A queste ragioni, si aggiunge quella prevista all’articolo 143, ossia lo scioglimento di un comune per infiltrazioni o condizionamenti di stampo mafioso.
Fra il 2013 e il 2016, secondo i dati provenienti dal Ministero dell’Interno, sono stati decisi 657 commissariamenti in 623 comuni (di cui, dunque, 34 commissariati due volte nel periodo preso in considerazione).
| Causa di commissariamento | 2013 | 2014 | 2015 | 2016 | Tot. |
| Dimissioni del sindaco | 43 | 32 | 25 | 37 | 137 |
| Dimissioni dei consiglieri | 71 | 66 | 62 | 69 | 268 |
| Mozione di sfiducia | 4 | 2 | 6 | 4 | 16 |
| Dissesto di bilancio o mancata approvazione | 9 | 6 | 8 | 9 | 32 |
| Decadenza del sindaco | 26 | 7 | 24 | 5 | 62 |
| Decesso del sindaco | 26 | 15 | 20 | 20 | 81 |
| Impedimento del sindaco | 0 | 0 | 0 | 2 | 2 |
| Infiltrazioni mafiose (incluse proroghe) | 35 | 11 | 6 | 7 | 59 |
La regione con il maggior numero di commissariamenti è la Campania (112 provvedimenti), che detiene anche i record di scioglimenti avvenuti per ragioni di bilancio (11), così come per dimissioni di massa del consiglio comunale (60).
In termini assoluti, al secondo posto troviamo la Lombardia (99 commissariamenti, di cui 24 dovuti a dimissioni del sindaco), seguita dalla Calabria (80, di cui 27 per infiltrazioni mafiose), dal Piemonte (64) e dalla Puglia (52). Nessun caso risulta per le regioni Valle d’Aosta, Friuli-Venezia Giulia e Sardegna.

Vale la pena notare come la Sicilia, in questa analisi, detenga un poco invidiabile primato: mentre tutte le altre regioni presentano una pluralità di cause di scioglimento, tutti e 13 i commissariamenti che l’hanno riguardata nel quadriennio analizzato sono avvenuti per mafia.
Da un punto di vista cronologico, il 2013 è stato l’anno con il maggior numero di commissariamenti (214 in tutto), così come l’anno con il maggior numero di provvedimenti presi per infiltrazione mafiosa (35, poco meno del 60% di tutto il periodo considerato).

Il 2016, invece, si segnala per l’alto numero di “ri-commissariamenti”: 18 in tutto, di cui 13 presi nei confronti di comuni già sciolti nel 2013 e di cui 9 per motivi di infiltrazione mafiosa.
Fra questi ultimi, spicca il caso del comune di Nardodipace (VV): sciolto la prima volta per mafia nel dicembre 2011, il commissariamento fu poi man mano prorogato fino ai limiti di legge (24 mesi massimo) dall’allora ministro dell’Interno Angelino Alfano. Il comune è stato poi nuovamente sciolto nel dicembre del 2015, sempre per infiltrazione mafiosa (e, anche in questo caso, il provvedimento è stato prorogato fino ai termini di legge dall’allora ministro Marco Minniti).
| Anno del primo scioglimento | 2013 | 2014 | 2015 | 2016 |
| 2013 | 2 | 5 | 6 | 13 |
| 2014 | – | 0 | 3 | 2 |
| 2015 | – | – | 0 | 0 |
| 2016 | – | – | – | 3 |
Per quanto faccia molto più scalpore (per ovvie e comprensibili ragioni), nel periodo considerato la mafia è coinvolta soltanto nel 9% dei casi trattati e risulta essere addirittura il quarto motivo di scioglimento.
In ben 4 casi su 10, infatti, sono state le dimissioni in massa dei consiglieri comunali a determinare il commissariamento del comune. Il caso più eclatante è stato quello del comune di Roma Capitale, dove è stata addirittura la maggioranza a provocare nel 2015 lo scioglimento del comune e il successivo commissariamento.
Nel 20,85% dei casi sono state invece le dimissioni del sindaco a porre termine in modo anticipato alla legislatura consiliare, mentre la terza ragione in termini assoluti è il decesso in officio del sindaco (81 casi, di cui 20 avvenuti in Piemonte e 18 in Lombardia).

Ampliando un po’ la visione, l’analisi degli indicatori socio-economici dei comuni oggetto di commissariamento lascia pensare che sia perlopiù la stagnazione economica a “contribuire” nel profondo, piuttosto che il “degrado sociale” (reale o percepito) o i condizionamenti mafiosi.
Analizzando la relativa diseguaglianza nella distribuzione della ricchezza, attraverso il coefficiente di Gini, si nota come oltre il 70% dei commissariamenti avvenga in comuni dove tale diseguaglianza non è così marcata (ovvero, nel grafico qui sotto, i comuni con un indice compreso fra 0,18 e 0,22).
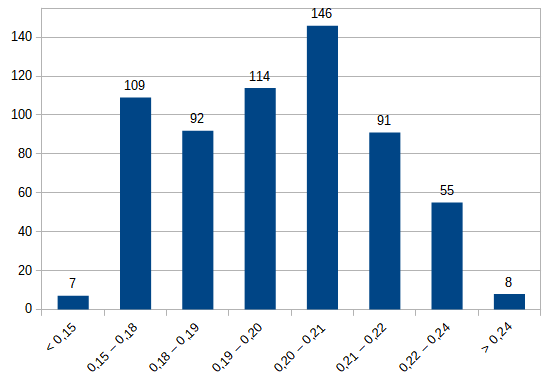
Stessa considerazione si può fare se si prende in considerazione il tasso di occupazione medio: l’analisi condotta dimostra peraltro il rischio di generare una falsa correlazione fra questo e altri fattori (dal momento che larghissima parte dei comuni con occupazione sotto il 40% si trovano nel meridione).

Salta invece all’occhio la fortissima incidenza di commissariamenti in quei comuni il cui indice di dinamismo economico (prodotto in base alle medie degli occupati nei settori primario, secondario e terziario) risulta estremamente basso, se non addirittura negativo: l’83% circa dei casi di commissariamento rientra in questa fattispecie (indice pari o inferiore a 0,4), di cui addirittura il 61,32% riguarda comuni con un indice negativo.
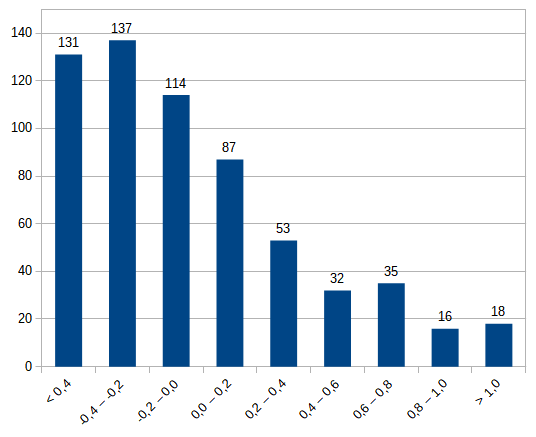
Si può dunque supporre che la debolezza del tessuto produttivo del comune contribuisca notevolmente a indebolire anche il tessuto politico dello stesso, preparando potenzialmente il terreno per instabilità politiche e, nelle zone più a rischio, anche condizionamenti da parte della criminalità organizzata.
Il discorso diventa ancora più serio se si considera che sono 5 i casi di commissariamento per mafia verificatisi al nord Italia durante il periodo considerato (di questi, 3 provvedimenti costituivano proroghe di commissariamenti in atto). Un dato che sottolinea come l’allargamento a tutto il territorio nazionale del fenomeno dell’infiltrazione mafiosa fosse già iniziato anni prima e venuto a galla “ufficialmente” soltanto in quel periodo.
Disclaimer: questo post è stato realizzato come prova per un colloquio di lavoro che ho fatto qualche mese fa e che, purtroppo, non si è concluso bene. Arrivati a questo punto, lo pubblico, casomai possa interessare a qualcuno.
Il 2019 sarà un anno pieno di appuntamenti elettorali per il nostro Paese: oltre alle elezioni per il Parlamento europeo e alle elezioni amministrative (entrambe previste per il 26 maggio prossimo, con un turno di ballottaggio eventuale per le sole amministrative il 9 giugno), anche sei regioni saranno chiamate a rinnovare i propri consigli regionali.

L’Abruzzo sarà la prima delle sei regioni a recarsi al voto, il prossimo 10 febbraio. Si tratta anche dell’unica regione a dover ricorrere alle elezioni anticipate (sebbene solo di qualche mese rispetto alla data naturale), in seguito alla decadenza per incompatibilità del Presidente uscente Luciano D’Alfonso (eletto senatore del PD alle elezioni politiche dell’anno scorso).
Seguiranno poi la Sardegna (24 febbraio), la Basilicata (24 marzo), il Piemonte (il 26 maggio, in concomitanza con le elezioni europee e il primo turno delle amministrative), la Calabria e l’Emilia-Romagna (in data da stabilire, ma comunque si prevede entro fine novembre).
In ragione di questo appuntamento, abbiamo deciso di analizzare quanto e come i gruppi consiliari regionali uscenti abbiano speso, nel corso della legislatura che si sta chiudendo, in tre delle sei regioni che andranno al voto. La scelta è ricaduta su Abruzzo, Calabria e Piemonte, sia per motivi geografici (ciascuna regione rappresenta un’area del nostro Paese), sia perché le rispettive elezioni si terranno in un momento diverso dalle altre due.
In tutti e tre i casi, si tratta di regioni a statuto ordinario, che affronteranno quest’anno la loro undicesima tornata elettorale dalla loro costituzione (1970) e la cui maggioranza uscente di centro-sinistra (a guida PD) si è formata in seguito a un cambio di maggioranza alle ultime elezioni del 2014. Ciascuna regione, tuttavia, ha delle particolarità che verranno analizzate più nello specifico all’interno di ciascuna sezione dedicata.
La normativa sulle dotazioni economiche dei gruppi consiliari regionali si basa sul decreto legge 174/2012 e sulla successiva intesa raggiunta nella Conferenza Stato-Regioni, in base ai quali vengono fissati i principi comuni sulla quantità e sulla modalità di impiego dei fondi per i gruppi e viene attribuito alle sezioni regionali della Corte dei conti il compito di vigilare sulla corretta rendicontazione di queste spese.
Le categorie di spesa (e le relative dotazioni) sono suddivise in due macro-aree: “spese per il personale” (collaboratori, consulenti, eccetera) e “spese per il funzionamento” (uffici, linee telefoniche, stampa, cancelleria, promozione, eccetera). Ogni macro-area ha al suo interno altre sotto-voci di spesa, dove far rientrare le spese idonee alla funzione parlamentare.
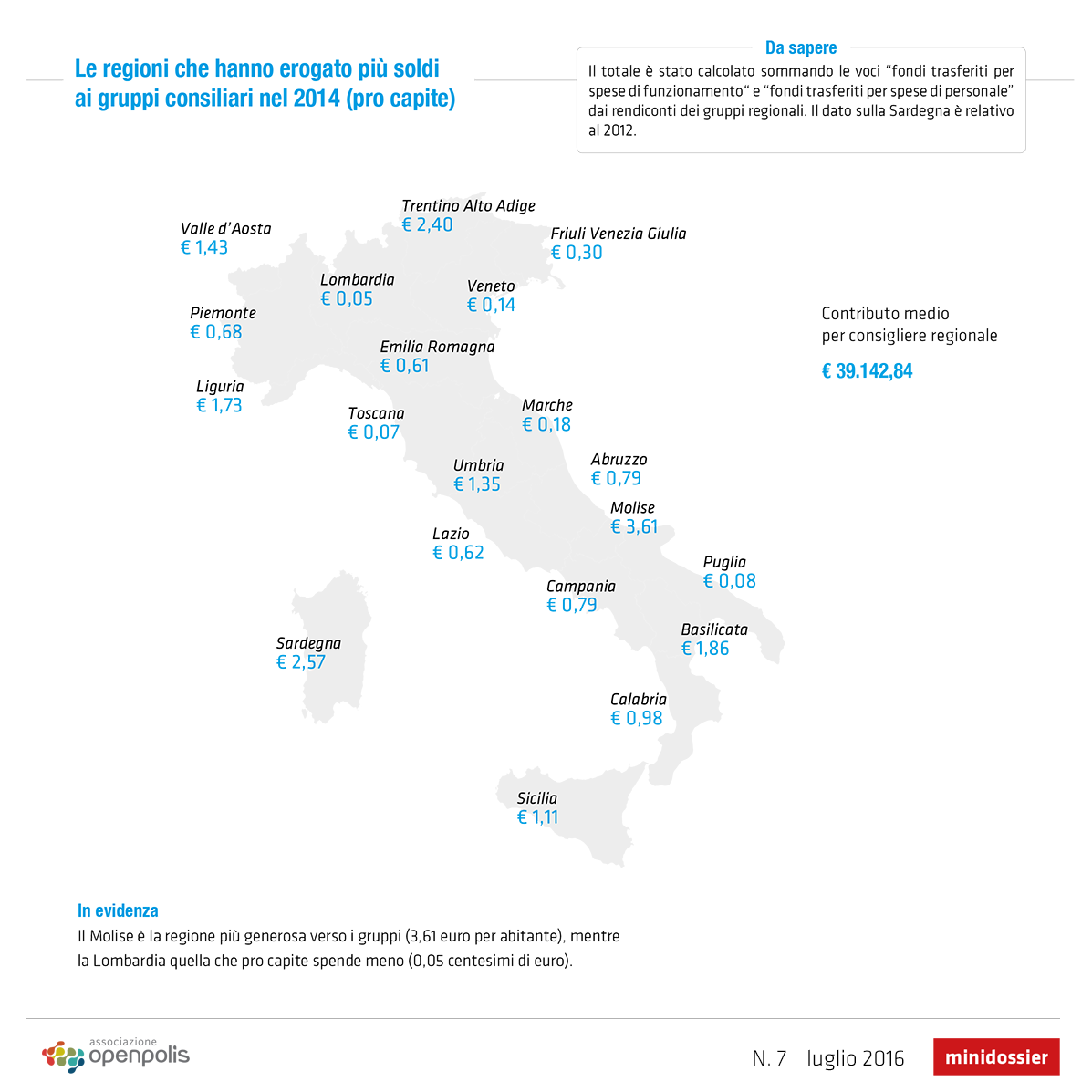
Mentre le regole e le voci di spesa sono uniche per tutte le Regioni, il contributo riconosciuto per ciascuna macro-area a ciascun consigliere regionale varia a seconda della regione. In media, sommando le due macro-voci di spesa, si arriva a circa 39mila euro all’anno per ciascun consigliere (per un veloce approfondimento in materia, vedi qui).
Ogni anno, ciascun gruppo deve presentare entro il 31 gennaio un rendiconto dettagliato delle proprie spese (e le relative “pezze d’appoggio”) relativo all’anno precedente. Questo rendiconto viene poi inviato alla sezione regionale di competenza della Corte dei Conti, la quale poi valuta l’idoneità di queste spese nei successivi 60 giorni. In caso di spesa giudicata “non idonea”, il gruppo è tenuto a rimborsare tempestivamente la quota indicata dalla Corte dei Conti.
I dati qui analizzati coprono soltanto il periodo che va dall’inizio della legislatura (la seconda metà del 2014) fino al 31 dicembre 2017 e si basano sui rendiconti presentati da ciascun gruppo parlamentare, disponibili sui siti dei rispettivi Consigli regionali. Non sono disponibili dati per il 2018, dal momento che i rendiconti sono ancora al vaglio della Corte dei conti alla data in cui scriviamo.
I dataset completi (in formato xls) sono disponibili a questo link.
Si è cercato di mantenere quanto più possibile aderenza allo schema fornito dalla Conferenza Stato-Regioni per rendicontare le spese. Si fa notare al riguardo che, rispetto allo schema iniziale:
Riguardo le singole sezioni, ogni resoconto è composto da una introduzione generale sul Consiglio generale e sulla situazione dei gruppi di ciascuna regione, seguita da un commento più particolare riguardo i singoli dati.
In seguito alla riforma del 2013, il Consiglio regionale in Abruzzo è composto da 31 membri (rispetto ai 45 della legislatura 2009–2014), ripartiti su quattro circoscrizioni provinciali ed eletti secondo il sistema proporzionale (metodo D’Hondt). Nel caso in cui la coalizione vincente non ottenga il 60% o più dei voti validi, le viene garantito un premio di maggioranza, tramite l’elezione dei componenti del “listino regionale” collegato al Presidente vincente.
La vittoria nel 2014 è andata con il 46,26% dei voti alla coalizione di centro-sinistra, guidata dall’ex presidente della Provincia di Pescara Luciano D’Alfonso. Hanno ottenuto seggi in Consiglio la coalizione di centro-destra (guidata dal presidente uscente Giovanni Chiodi) con il 29,26% dei voti e il Movimento Cinque Stelle (al suo esordio alle elezioni regionali) con il 21,41% dei voti.
| Partito | 2014 | 2015 | 2016 | 2017 | 2018 |
| Partito Democratico | 11 | 11 | 11 | 10 | 9 |
| Regione Facile | 2 | 2 | 2 | 2 | 3 |
| Abruzzo Civico | 2 | 2 | 2 | 2 | 2 |
| Sinistra Ecologia Libertà | 1 | 1 | 1 | 2 | 2 |
| Centro Democratico | 1 | 1 | 1 | 1 | 1 |
| Italia dei Valori | 1 | 1 | 1 | 1 | 1 |
| Totale maggioranza | 18 | 18 | 18 | 18 | 18 |
| Movimento Cinque Stelle | 6 | 5 | 5 | 5 | 5 |
| Forza Italia | 5 | 5 | 5 | 5 | 5 |
| Nuovo Centro-Destra / Alleanza Popolare* | 1 | 1 | 1 | 1 | 1 |
| Abruzzo Futuro | 1 | 1 | 1 | 1 | 1 |
| Gruppo misto | 0 | 1 | 1 | 1 | 1 |
| Totale opposizione | 13 | 13 | 13 | 13 | 13 |
(*) Il gruppo ha cambiato nome il 21 settembre 2017.
La composizione dei gruppi è rimasta, come si può osservare, sostanzialmente uniforme lungo tutta la legislatura, con sole tre fuoriuscite: l’ex grillino Leandro Bracco, espulso dal gruppo M5s il 29 giugno 2015, e i due ex-democratici Marinella Sclocco (che ha aderito al gruppo di SEL il 3 aprile 2017) e Bartolomeo Di Matteo (che ha aderito al gruppo di Regione Facile il 14 febbraio 2018).
Il contributo riconosciuto dalla Regione Abruzzo a ogni consigliere regionale è di 7.151,52 euro per le spese di funzionamento del gruppo e di 43.305,48 euro per le spese per il personale (aumentati nel 2016 a 55.028,54 euro).
In totale, nel periodo preso in considerazione sono stati distribuiti 5.702.732,55 euro, di cui 782.430,72 euro (il 13,72% del totale) per il funzionamento dei gruppi e 4.920.301,83 euro (il restante 86,28%) per le spese di personale. Tuttavia, soltanto 5.015.391,80 euro sono stati effettivamente spesi dai gruppi regionali (con un risparmio del 13,54% rispetto alla dotazione iniziale).

La parte del leone è ovviamente toccata al personale (4.337.753,44 euro complessivi fra stipendi e contributi, pari all’86,49%). Va notato, in tal senso, come l’aumento del contributo per il personale effettuato a metà legislatura sia stato perlopiù destinato all’aumento dei contributi dei collaboratori (passati da un’incidenza di spesa del 23,55% di inizio legislatura al 35,85% del 2017).
La seconda voce di spesa per importanza è stata quella relativa a “consulenze, studi e incarichi”, per cui sono stati spesi 416.954,21 euro (8,31% del totale). Il partito che ha speso di più in termini assoluti è stato il Partito Democratico (155.180,95 euro, pari al 76,35% delle spese di funzionamento), mentre in termini relativi ben tre gruppi (Regione Facile, Abruzzo Civico e il componente del gruppo misto) vi hanno allocato oltre il 90% delle proprie spese di legislatura (rispettivamente 31.845,70 euro, 33.351,94 euro e 16.061,58 euro).
Il restante 5,78% di spesa (pari a complessivi 260.684,15 euro) è stato effettuato per tutte le altre voci, fra cui ufficio, cancelleria, spese postali, materiali di comunicazione, rimborsi spese, eccetera.

In generale, si può dire che i consiglieri abruzzesi hanno condotto nel periodo analizzato una buona politica di contenimento dei costi, che è stata annualmente riconosciuta anche dalla Corte dei conti nelle sue relazioni finali.
La stessa Corte ha anche notato costanti irregolarità nell’attribuire le spese alle corrette voci di rendiconto: se spesso queste irregolarità si sono risolte con una semplice riclassificazione delle spese, talvolta la Corte ha chiesto la restituzione delle somme “non ammissibili”. Su questo fronte, il gruppo maggiormente colpito è stato quello di Forza Italia, che ha dovuto restituire ben 62.285,95 euro, seguito dal Nuovo Centro-Destra (1.282,10 euro) e da Regione Facile (442,21 euro).
In seguito alle riforme dello Statuto e della legge elettorale, entrambe del 2014, il Consiglio regionale in Calabria è composto da 31 membri (rispetto ai 50 della legislatura 2010–2014), ripartiti su tre circoscrizioni (rispettivamente composte dalla provincia di Catanzaro, dalla provincia di Cosenza e dalle province di Reggio Calabria, Crotone e Vibo Valentia) ed eletti secondo il sistema proporzionale.
Hanno accesso alla ripartizione dei seggi le coalizioni o le liste singole che superano l’8% su base regionale, così come le liste di una singola coalizione che superano il 4% (sempre su base regionale). Alla coalizione o lista vincente, viene comunque garantito un premio di maggioranza pari al 55% dei seggi.
La vittoria nel 2014 è andata con il 61,41% dei voti alla coalizione di centro-sinistra, guidata dall’ex presidente della Provincia di Cosenza Mario Oliverio. Hanno ottenuto seggi in Consiglio la coalizione di centro-destra fra Forza Italia e Fratelli d’Italia (guidata dalla forzista Wanda Ferro) con il 23,58% dei voti e l’altra coalizione di centro-destra fra NCD e UDC (guidata da Nico D’Ascola) con l’8,70% dei voti.
| Partito | 2015 | 2016 | 2017 | 2018 |
| Partito Democratico | 10 | 10 | 10 | 10 |
| Oliverio Presidente | 5 | 5 | 4 | 3 |
| Democratici Progressisti | 3 | 3 | 3 | 2 |
| Calabria in Rete | 1 | 1 | 1 | 1 |
| La Sinistra | 1 | 1 | 1 | 1 |
| Totale maggioranza | 20 | 20 | 19 | 17 |
| Forza Italia | 3* | 3 | 2 | 2 |
| Casa delle Libertà | 3 | 3 | 2 | 2 |
| Nuovo Centro-Destra | 3 | 3 | 3 | 4 |
| Gruppo misto | 2* | 2 | 5 | 4 |
| Totale opposizione | 11 | 11 | 12 | 12 |
(*) Forza Italia aveva 5 seggi alla costituzione del gruppo, ma dopo due settimane due membri sono fuoriusciti.
La composizione dei gruppi è variata in due momenti separati: nel primo mese di legislatura, con la fuoriuscita di due consiglieri dal gruppo di Forza Italia (confluiti nel Gruppo misto) e a partire dalla seconda metà della legislatura, con varie fuoriuscite di consiglieri (quasi sempre verso il Gruppo misto e soprattutto a danno della maggioranza).
Il contributo riconosciuto dalla Regione Calabria a ogni consigliere regionale è di 8.159,75 euro per le spese di funzionamento del gruppo e di 42.860,38 euro per le spese per il personale.
In totale, nel periodo preso in considerazione sono stati distribuiti 4.273.427,38 euro, di cui 757.357,68 euro (il 17,73% del totale) per il funzionamento dei gruppi e 3.514.569,08 euro (il restante 82,27%) per le spese di personale. Tuttavia, soltanto 3.831.114,07 euro sono stati effettivamente spesi dai gruppi regionali (con un risparmio del 10,35% rispetto alla dotazione iniziale).
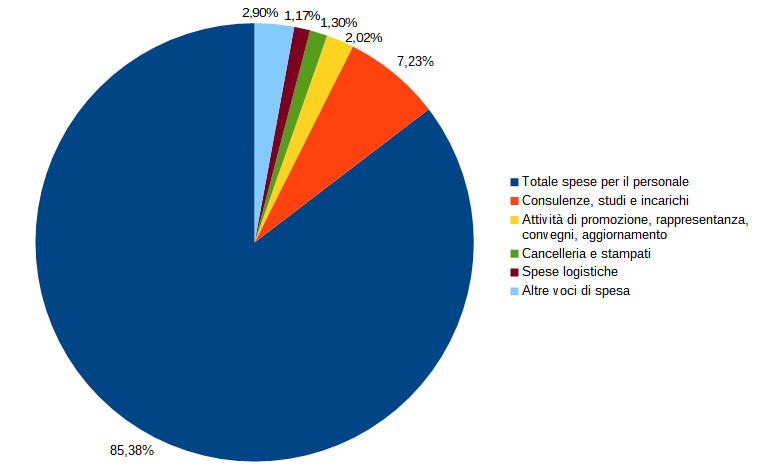
Anche in questo caso, le spese per il personale costituiscono la magna pars delle uscite (3.271.102,06 euro complessivi fra stipendi e contributi, pari all’85,38%). Parimenti, la seconda spesa per importanza è anche qui quella per “consulenze, studi e incarichi”, per cui sono stati spesi 276.843,54 euro (7,23% del totale).
A differire rispetto all’esempio abruzzese è invece la ripartizione del restante 7,39% di spesa (pari a complessivi 283.168,47 euro): risultano infatti lievemente più alte tutte le spese, in particolare quelle per le “Attività di promozione, rappresentanza, convegni, aggiornamento” (77.560,52 euro, 2,02% della spesa), per “Cancelleria e stampati” (49.686,10 euro, 1,30% della spesa) e le “Spese logistiche” (44.827,98 euro, 1,17% della spesa).
Nonostante questo, si può dire che anche i consiglieri calabresi siano più o meno riusciti nel contenere i costi. Meno commendevole, invece, è la parte relativa alla rendicontazione, che è spesso contraddittoria, in particolare nella dichiarazione dei fondi residui fra un anno e l’altro (dettaglio questo che ha complicato non poco l’analisi).
Anche in questo caso, la Corte dei Conti ha riscontrato più di una irregolarità nell’attribuire le spese alle corrette voci di rendiconto, ma tutte le istruttorie condotte si sono risolte con un sostanziale chiarimento fra le parti.
Il Consiglio regionale in Piemonte è composto da 50 membri, ripartiti su otto circoscrizioni su base provinciale ed eletti secondo il sistema proporzionale. Alla coalizione o lista vincente, viene comunque garantito un premio di maggioranza pari al 55% dei seggi. Il candidato vincente, inoltre, elegge in blocco tutti i candidati con il proprio “listino regionale”. Un seggio è attribuito di diritto al secondo candidato presidente più votato.
La vittoria nel 2014 è andata con il 47,09% dei voti alla coalizione di centro-sinistra, guidata dall’ex sindaco di Torino Sergio Chiamparino. Hanno ottenuto seggi in Consiglio la coalizione di centro-destra (guidata dal vicepresidente uscente Gilberto Pichetto) con il 22,09% dei voti, il Movimento Cinque Stelle con il 21,45% dei voti e Fratelli d’Italia con il 5,24% dei voti.
| Partito | 2015 | 2016 | 2017 | 2018 |
| Partito Democratico | 26* | 26 | 24 | 24 |
| Liberi e Uguali | 0 | 0 | 0 | 3 |
| Moderati | 2 | 2 | 2 | 3 |
| Chiamparino per il Piemonte | 2 | 2 | 2 | 2 |
| Sinistra Ecologia Libertà | 2 | 2 | 2 | 1 |
| Scelta di Rete Civica per Chiamparino | 1* | 1 | 1 | 1 |
| Art. 1 – MDP | 0 | 0 | 2 | 0 |
| Totale maggioranza | 33 | 33 | 33 | 34 |
| Movimento 5 Stelle | 8 | 8 | 7 | 7 |
| Forza Italia | 7 | 7 | 6 | 5 |
| Lega Nord | 2 | 2 | 2 | 2 |
| Fratelli d’Italia | 1 | 1 | 1 | 2 |
| Gruppo misto – Movimento per la sovranità | 0 | 0 | 1 | 1 |
| Gruppo misto – Movimento libero e indipendente | 0 | 0 | 1 | 0 |
| Totale opposizione | 18 | 18 | 18 | 17 |
(*) Nel corso del primo anno, un consigliere di Scelta Civica aderisce al PD.
La composizione dei gruppi è variata costantemente lungo tutta la legislatura, anche se questo non ha influito granché sulle dinamiche fra maggioranza e opposizione. I cambi di gruppo, infatti, sono perlopiù avvenuti all’interno delle due aree, con l’unica eccezione del passaggio di Stefania Batzella dal gruppo del Movimento 5 Stelle al gruppo misto, al gruppo dei Moderati.
A partire dal 2014, la Regione Piemonte ha abolito i contributi per le spese di funzionamento del gruppo e quindi fornisce soltanto un contributo per le spese per il personale. In totale, nel periodo preso in considerazione sono stati distribuiti e spesi 7.218.203,45 euro.
Il partito che ha ottenuto (e speso) la maggior quota di finanziamenti è il Partito Democratico (3.255.354,74 euro, pari al 45,10% della quota complessiva), seguito a notevole distanza dal Movimento 5 Stelle (374.571,99 euro, 16,38% del totale), Forza Italia (329.096,20 euro, 14,39% del totale) e Lega Nord (109.442,73 euro, 4,79% del totale).
Il problema di questa analisi è che i rendiconti pubblicati dai gruppi indicano esclusivamente la cifra per il personale, sia in entrata, sia in uscita. Non c’è alcun dettaglio aggiuntivo, né una spiegazione (per esempio) del perché, col progredire della legislatura, i costi per il personale in certi casi aumentino, nonostante il numero di consiglieri rimanga stabile.

Non a caso, questa situazione viene sottolineata ogni anno dalla Corte dei Conti, nella sua analisi dei conti della Regione, anche in maniera piuttosto esplicita: “l’interpretazione ed il modus operandi adottato dal Consiglio [del Piemonte, ndr] rendono impossibile l’espletamento della funzione di controllo intestata alla Corte dei Conti, funzione che certamente non può esplicitarsi in un controllo esclusivamente formale ed in una mera “presa d’atto” di un dato da altri fornito, senza alcun tipo di documentazione giustificativa a supporto. Si tratta, pertanto, di una precisa scelta dell’organo legislativo che, allo stato, di fatto preclude l’esercizio della funzione di controllo”.
La trasparenza sui conti dei gruppi consiliari regionali ha fatto grossi passi in avanti dallo scandalo di “Rimborsopoli” a oggi, anche e soprattutto nel costringere i consiglieri a una più accorta gestione dei fondi regionali.
Come abbiamo potuto vedere, ci sono ancora problemi nell’applicazione delle regole: alcuni probabilmente, nel corso della prossima legislatura, verranno ulteriormente limitati dalla pratica; altri potranno essere invece risolti soltanto con una chiara richiesta, da parte del corpo elettorale, di maggiore trasparenza nei conti, perché è la trasparenza (e non solo il “risparmio”) a garantire che i soldi pubblici vengano ben spesi.
Ndr: il titolo di questo post è un gioco di parole rispetto a quello del mio post precedente.
“Ma come cazzo abbiamo fatto a ridurci così?” chiede un amico che mi posta il grafico dell’andamento del rapporto debito/PIL italiano negli ultimi 10/15 anni o giù di lì.
Il grafico non lo riesco a trovare, ma grazie a Gogol’ abbiamo una infografica interattiva che va dal 1995 al 2017 (con tanto di impietoso confronto con Francia e Germania), da cui si nota che il trend del debito era in calo fino al 2007 e che si è improvvisamente invertito a partire dal 2008.
Che è successo? Ho provato a sintetizzarlo in una serie di punti, quindi scusate la schematicità del post.
Continua a leggere
Oggi, al contrario del solito, ho voglia di rendere la mia “pausa” dal lavoro un po’ più “produttiva” del solito. O almeno provare a farlo.
Oggi voglio scrivere dei massimi sistemi, visto che spesso mi limito solo ad arrovellarmici sopra senza trovare una risposta che sia una alle domande che mi pongo. Non che scrivere mi aiuti a trovarle, ma almeno impiego il tempo che mi separa dal mio appuntamento di oggi pomeriggio in un modo più creativo.
* * *
Riflettevo sul mercato dei servizi di manutenzione domestica in Italia. In altre parole, riflettevo sull’esercito di antennisti, elettricisti, pittori, idraulici, riparatori, eccetera del nostro Paese, quelli che “sono 100 euro, 80 senza fattura”.
Riflettevo su un commento che ho letto in giro per Facebook e che mi ha colpito perché tutt’altro che stupido: in questi mercati, sarebbe in realtà molto semplice operare delle economie di scala che “superino” l’attuale condizione fatta di una miriade di partite IVA individuali e di ditte “familiari” – per non parlare dei professionisti che basano larga parte del proprio reddito sul nero.
Semplificando tantissimo il discorso: se una decina di idraulici si mettessero d’accordo per stabilire un prezzario comune e andare da alcuni amministratori di condominio a negoziare un accordo di collaborazione, le loro probabilità di tornare a casa con un reddito stabile (e forse maggiore di quello che producono oggi) sarebbero maggiori. Non solo: i costi per attrezzatura e pezzi di ricambio sarebbero più sostenibili; si creerebbero pure un paio di posti di lavoro in più per organizzare turni e chiamate, per tenere in ordine i conti e il magazzino, eccetera; si potrebbe perfino estendere i servizi, mettendo nel mazzo anche i già citati pittori, elettricisti, antennisti, riparatori, eccetera; e perché no, fare un’app per prenotare il servizio che ti serve.
Mi domando allora: perché non ci ha ancora pensato nessuno? Perché nessuno ha pensato di realizzare non dico “una Amazon della manutenzione domestica”, ma una più prosaica società cooperativa di dimensioni sufficienti a strutturarsi su tutto il comune di una città medio-grande? Non conosco le storture legislative e non ho compiuto nessuna analisi di mercato in materia, in altre parole mi mancano i dati per spiegarmi perché questo non sia ancora successo (anche se immagino che ci siano, innanzitutto, dei problemi di sostenibilità economica non indifferenti alla base di questa situazione).
Quello che vedo è che ci sono moltissimi professionisti che, di fatto, si barcamenano sulla linea della sussistenza, perché sono “piccoli”. Essere piccolo in un mondo come questo, dove la competizione è durissima e la qualità media di beni e servizi tende ad aumentare sempre più, è come guidare un aereo in panne in cui solo una leva funziona, quella del prezzo – per di più in un verso solo, cioè verso il basso. Questo ti porta, volente o nolente, a fare prezzi più bassi con i quali non ci guadagni e non ci vivi, a meno di non ricorrere a pratiche sleali come l’evasione (evidenzio l’aggettivo “sleali” perché non vorrei che poi suonasse come una piena giustificazione, tutt’altro).
Il vero problema di tutto questo è che la slealtà del manutentore occasionale a non rilasciare la fattura di fatto conviene anche a me e a te, perché quei 20-30 euro in meno di spesa fanno sempre comodo. Nel complessivo, è una situazione “comodamente disfunzionale” che permette a tutti di non affrontare il problema e di tirare in avanti un altro po’, ma che non è efficiente (perché si potrebbe fare di più e meglio) e non è nemmeno giusta (perché mentre tu paghi tutte le tasse fino all’ultimo, quello lì non lo farà del tutto o non lo farà affatto).
* * *
Ipotizziamo per assurdo (cit.) che si riesca a consolidare il mercato dei servizi di manutenzione domestica e che la cosa tenga. C’è un altro problema da risolvere: gli esclusi. Perché puoi essere certo di tre cose nella vita: le tasse, la morte e la disoccupazione frizionale. In particolare in Italia, dove prima si fanno le riforme e poi ci si “dimentica” di mettere in campo i correttivi e i sostegni per chi viene penalizzato dalla riforma (riforma Biagi, anyone?).
Innanzitutto, è praticamente impossibile che tutti gli appartenenti alle categorie di cui sopra riescano a essere impiegati nel nuovo sistema. Ci sarà sempre una parte di offerta di lavoro che non verrà mai soddisfatta, perché verrà da operatori troppo in là con l’età e/o troppo di scarsa qualità per essere assunti da aziende del genere, ossia da persone che “costa troppo riqualificare”.
Come gestiamo queste persone? I più fortunati potranno sfruttare (forse) il sussidio di disoccupazione, che comunque dura 18 mesi e va a scalare di 6 mesi in 6 mesi – e questi, ripeto, sono i fortunati. Con gli altri che facciamo? Le strutture per aiutare questa gente ad affrontare la riconversione di fatto non esistono, perché i pochi Centri per l’impiego esistenti sono strutturalmente incapaci di gestire l’attuale situazione.
Certo, se in 18 mesi non riesci a trovare un lavoro, può significare anche che non vuoi trovarlo, siamo d’accordo. Ma “dopo 18 mesi, ti arrangi” oppure “puoi sempre emigrare” possono bastare come risposte? Evidentemente no, vista la vittoria mostruosa del Fronte della Merda (Lega+M5S) alle ultime Politiche.
Ah, e non dimentichiamoci di quello che sta avvenendo attualmente con i vari servizi tramite app (Uber, Lyft, JustEat, Glovo, Booking, ecc.): migliaia di persone che lavorano per pochissimi euro, senza tutele e senza garanzie, ma soprattutto senza alcuna garanzia di poter fare carriera (cioè quella cosa che i nostri genitori sono riusciti a fare “per diritto” e che noi non sappiamo manco dove sta di casa).
Va bene chiamarli “lavoretti”, va bene ricordare che “con lavori del genere puoi solo arrotondare”, va bene perfino far notare che questi lavoretti esistevano già prima di queste app e che sono solo stati “innovati” il giusto per ottimizzare il processo. Anche qui, possono bastare queste come risposte? Evidentemente no, parte seconda.
* * *
Che soluzioni ci sono a tutto questo? Non lo so. Io non riesco seriamente a pensare una soluzione, senza pensare ai rischi che ciò potrebbe portare.
Per esempio, applicare le vecchie tutele e le vecchie regole alla nuova situazione rischia di soffocare una evoluzione del mercato verso una situazione più efficiente – per esempio, Uber ha comunque costretto le cooperative di taxi a passare alle app, mentre Flixbus ha rilanciato il trasporto su gomma che era diventato un monopolio quasi totale di Trenitalia (la quale s’è ben guardata dall’investire qualcosa per risistemare il parco macchine o guidatori).
Pure è vero, però, che le nuove piattaforme lucrano dai grandi numeri di proletari che si appoggiano a questo sistema e dall’incertezza normativa in cui operano. Chiamiamolo “metodo Ryanair”, dalla prima azienda che ha aggredito con successo il mercato del low-cost. Solo oggi, dopo circa 20 anni, le varie corti europee stanno riuscendo a imporre a Ryanair qualche regolamentazione in più sulla tutela dei lavoratori. Nel frattempo, tantissimi sono stati pagati con contratti e accordi che andavano quasi completamente a favore dei datori di lavoro, non di chi prestava lavoro.
Ce li abbiamo noi altri 20 anni per sistemare questo casino? Evidentemente no.
Da moltissimo tempo non parlo più volentieri di politica. Non lo faccio (solo) perché mi fa schifo quello che mi sta intorno, ma perché l’argomento porta con sé una serie di piccole ferite che mi fa male ammettere – la “peggiore” delle quali quella del mio fallimento con Fare per Fermare il Declino, dopo la quale ho smesso di pensare di essere adatto a quel mondo lì.
Ho smesso di pensarlo perché ricordo quella sera dopo le elezioni, in cui una quindicina di candidati (fra cui il sottoscritto) si incontrarono in pizzeria per fare i conti con la sconfitta e leccarsi le ferite. Ricordo che, dopo la cena, due ex candidate mi si avvicinarono timorose, chiedendomi perché io avessi messo in giro delle voci false su di loro. Ricordo che le guardai come si guardano due pazze e spergiurai di non averlo mai fatto – anche perché effettivamente non lo feci mai. Ricordo che pensai: «Ma davvero qualcuno s’è preso la briga di mettermi in mezzo a una stronzata del genere, e perché poi? Davvero pensavamo di avere delle speranze? Davvero pensavamo di essere qualcosa di diverso da dei semplici portatori d’acqua?»
Perché non giriamoci intorno, la politica è questo. La politica è affare di gente di coltello e io dovevo sbatterci il muso per capire che io persona di coltello non sono. Quell’esperienza mi ha fatto capire che la politica da candidato non fa per me. Purtroppo, non lo ricordo con piacere, perché un fallimento non fa mai piacere ricordarlo, ma tant’è.
***
Ho iniziato con un ricordo personale perché mi sembrava giusto farlo e perché volevo sgomberare il campo da potenziali dubbi. Anzi, per essere ulteriormente sicuri, lo dico qui: io sono radicale. Sono filo-israeliano, filo-americano, filo-europeista e filo-atlantista. Sono per i diritti civili, sono per la regolamentazione (leggera e quanto più permissiva possibile) delle droghe leggere, dell’eutanasia, dell’aborto, della fecondazione assistita e di tutto quello che può assomigliare a un discorso vagamente “sensibile”. Credo fortemente che la libertà economica e la libertà civile/sociale non esistano da sole, ma esistano solo assieme e che siano inscindibili l’una dall’altra. Credo che Benedetto Croce sia stato (per questo motivo e per l’altra grande stronzata del far prevalere la conoscenza classica sulla conoscenza scientifica) il peggiore male che l’Italia abbia mai avuto, forse pari solo al Fascismo.
Credo inoltre tutto ciò che discende da queste pochissime linee guida, compreso il fatto che, se mi giudichi un coglione per una di queste cose, puoi benissimo ficcarti una zucchina in culo e tornare a casa saltellando al ritmo de La cucaracha. D’altronde, non ho fatto altro per tutta la mia vita che prendermi prese in giro, risate e risatine, sputi, insulti, ditini alzati e spiegazioni di come io sia un coglione a essere (non pensare, essere) come sono, e cioè sempre e comunque inadeguato, sbagliato e incapace.
La cosa che è cambiata nell’ultimo anno e rotti è che (forse) ho capito che io non devo nessuna spiegazione a te che leggi o a chiunque altro di chi io sia o di come io la pensi. Così è: ti piace, bene; non ti piace, fattene una ragione, perché a me poco me ne fotte.
***
Uno dei corollari dei due punti di cui sopra è che, lungo questi anni e queste esperienze, ho conosciuto anche delle persone. Brave persone e persone di merda. Persone che ci credevano e persone che ci marciavano. Dolci e straordinarie, emeriti imbecilli e figli di mignotta – con questi ultimi due tratti che, spesso, si presentavano insieme. Insomma, persone. Poi c’erano quelli che “ah sei liberale quindi”, che possono tranquillamente rileggersi il pezzo di sopra, ma questi non contano perché stavolta «hanno quasi ragione» (cit.).
Col passare del tempo, ho notato (eufemismo) come la parola “liberale” ormai fosse più comune del verderame nei campi ai bei tempi, fino ad arrivare al simpatico siparietto di qualche anno fa in cui Santoro e Travaglio si accusavano fra loro di essere illiberali e si pregiavano di essere più liberale dell’altro. Un po’ come “neoliberismo” o “blockchain” o “gender” o “petaloso”, la parola “liberale” ha perso qualsivoglia significato, diventando ciò che vogliamo che sia.
Il problema – quello che per me è ancora un problema grosso, perché insiste sulla mia identità – è che molti di quelli che si dicono liberali sono poi, gratta gratta, delle persone che:
Ora, a me di quello che questa gente grande, grossa e vaccinata (oddio, di ‘sti tempi…) decida più o meno consciamente di credere non me ne frega un cazzo. Sul serio, eh. Se con te trovo (altri) argomenti di conversazione, bene, sennò non me l’ha mica detto il dottore di continuare a frequentarti.
Comincia a fregarmene qualcosa, però, se decido di aderire a un movimento politico e me li trovo in mezzo alle palle. Perché una cosa è sentirmi dire che le mie idee sono stronzate, una cosa è sentirmi dire “ah ma allora sei d’accordo con X che dice Y” – dove Y è una stronzata colossale fra quelle di cui sopra e mi trovo a dovermi giustificare che “no, a dire il vero, la sua è una posizione personale e noi non la pensiamo così”, col danno che nel frattempo è stato ampiamente già fatto.
Me ne frega ancora di più se poi l’iniziativa fallisce, se ne fa un’altra e me li ritrovo un’altra volta in mezzo alle palle, senza che abbiano imparato un cazzo dal fallimento passato. Perché io un genio non sono, sennò non stavo qua a scrivere ‘ste stronzate, ma nemmeno sono irrimediabilmente fesso e qualcosina di molto, molto basilare, l’ho capita perfino io. Per esempio, ho imparato che se il problema risiede anche nelle persone di cui ti circondi, uno dei primi atti che bisogna compiere nel rialzarsi è allontanare quelle persone, subito, prima che possano reiterare il danno.
Perché loro, il danno, lo reitereranno, sempre, in una nevrotica ossessione per cui fare una lista di candidati è l’obiettivo che ci si pone da subito. Per cui si deve parlare solo di economia. Per cui bisogna fare come i meme su Apputin per cui “i musulmani si devono adeguare, sennò fuori dalle palle” – e poco importa se in Russia ci sono un botto di moschee (e di musulmani) e se uno dei suoi migliori amici è quel delinquente di Ramzan Kadyrov – e “mica li fanno gli attentati in Russia” (e infatti ne hanno fatti solo un paio l’anno scorso, di cui uno a San Pietroburgo, sua città natale, il giorno prima che fosse in città).
Per cui la Lista Laica Liberale Repubblicana Socialista Liberista Libertaria Libertina Intitolata a Qualche Grande Nome Che Si Richiama a Tale Tradizione (Di Cui al Popolo Non Gliene Frega un Cazzo, Né del Nome, Né della Tradizione)™ porterà sicuro vagonate di voti alle elezioni amministrative di Pavullo nel Frignano.
Per cui, anziché strutturare un programma politico serio con pochi punti chiari e una strategia con cui guardare da qui a 3-5 anni, è bene immediatamente buttarsi a suon di comunicati politici nella battaglia politica del momento, perché a tutti i giornali gliene frega qualcosa delle stronzate che hai da dire tu, ovviamente.
Per cui facciamo il movimento di opinione con la velleità di essere da subito un grande partito politico, senza avere un minimo di strutturazione territoriale e senza avere la più pallida idea di che cazzo dire e fare, anche perché appena ci provi arriva qualcuno che ti spiega perché non si può sostenere l’idea che hai tu. E questa è una storia vera, di quando in una riunione dei candidati di Fare mi permisi di chiedere quale fosse la posizione riguardo i diritti civili (avendo in mente che si poteva fare fronte comune coi radicali, da cui mi sentivo comunque un fuoriuscito e da cui comunque arrivavano un buon pezzo di militanti) e mi sentii rispondere “no, qui parliamo solo di temi economici” – che significava, in altri termini, che in lista c’erano persone che “froci di merda”. All’epoca, feci finta di nulla, anche perché pensai cinicamente che, forse, quelle persone portavano soldi e risorse, dunque era bene non mozzicare la mano che ti dava da mangiare (stiamo pur sempre parlando di un movimento appena nato). Solo dopo molto tempo, capii che non c’era nemmeno quella di motivazione e che l’errore da me commesso era molto, molto più profondo di quanto immaginassi.
***
Siccome «queste sono storie di un tempo ormai passato» (cit.), che l’errore, anzi, gli errori commessi hanno insegnato la loro lezione, mi fa piacere da un certo punto di vista vedere come il sottoscritto nemmeno sia stato considerato per la questione della raccolta delle firme dell’ultima lista prodotta. D’altra parte, tutto questo conferma il sospetto che, per certe persone, tu esisti solo fintanto e solo in relazione a quanto gli servi. Certo, anche questo non lo imparo oggi: non è la prima volta che mi succede in generale e dopo un po’ impari ad accettare la cosa e allontanarti, con dignità, nel silenzio.
Fa male però vederlo reiterato da persone con cui, comunque, hai collaborato e lavorato in passato, di cui ti sei fidato, che hai considerato in modo tutto sommato positivo. Fa ancora più male quando ti guardi indietro e non vedi errori da parte tua (il che ti sembra pure strano).
La domanda che ti poni dunque è: perché questa gente non impara? Le risposte sono due: o sono fessi in maniera irreversibile, o hanno comunque un vantaggio a provarci, provarci, provarci finché non ci riescono. Vorrei pure poter dire che la seconda categoria sia più grande della prima, ma non ne sono poi così tanto sicuro.
Poi ti rendi conto che la domanda è un’altra (“Ma io che ci guadagno a dargli una mano a questa gente?”) e che la risposta te la sei già data tempo fa (“Niente”). Ti rendi conto che la verità è che «non siete voi a essere utili a me, ma sono io che sono utile a voi, quindi siete voi che dovreste cercare di tenermi, non io a dover continuare a cercarvi» (cit.), a maggior ragione se quello che mi chiedi di fare è sbattermi gratis perché tu possa ottenere o mantenere il tuo posticino ai piedi del tavolo dove mangiano i padroni, rubacchiando le molliche che cadono. Ancor più a maggior ragione se la tua impresa è sempre più disperata di quanto già non fosse l’ultima e quel posticino sempre più difficile da raggiungere o tenere.
***
Questo post è stato a tratti volgare e in generale pesante. Lo so. Purtroppo, non mi si può chiedere di rimanere totalmente indifferente, specie quando, appunto, vedi coinvolte le tue idee e persone a cui hai voluto bene o che hai stimato. Anche io ci ho messo del mio, perché sono notoriamente persona dalla miccia corta.
Non per odio ho scritto questo sfogo, però: «hatred is too strong an emotion to waste on someone you don’t like» (cit.). L’ho scritto per insofferenza, per dispiacere e anche un po’ per pietà nel vedere certa gente ridursi a questo, pur di non affrontare la realtà dei fatti e cambiare vita, una volta e per tutte, o farsene una. E allora mi permetto di dire di sentirmi “migliore” di queste persone. Non perché mi senta realizzato (tutt’altro) o perché possa dire di aver capito cosa voglio fare, cosa so fare e cosa essere (tutt’altro), ma perché almeno sento di non avere più niente a che spartire con queste persone.
Avviso: Questo post è stato originariamente pubblicato il 30 novembre 2012 da Alex Bayley su infotrope.net, con licenza CC BY 3.0 Unported, ma allo stato non è più disponibile. Sperando di non incorrere nelle ire dell’autore, lo ripubblico sul mio blog, perché è un interessante analisi su quanto sia complicato lavorare con i dati aperti e su cosa può andare storto (hint: molte, molte cose).
Disclaimer: This post has been originally posted on November 30, 2012, by Alex Bayley on infotrope.net, under a CC BY 3.0 Unported license, but it is currently unavailable. Hoping not to bother the original author, I republish this post on my blog, because I think it is an interesting analysis about how complicated working with open data is and about what can go wrong (hint: lots of things, seriously a lot).
* * *
A few times on the Growstuff mailing list or IRC channel, someone’s excitedly suggested that we should import data from another CC-licensed data set. Each time, I say, “Trust me, that’s pretty complicated,” but I’ve never actually sat down and explained the full gory details of why.
The following is something I wrote up for our wiki so that I could point people at it next time the subject comes up. I thought it might be interesting to a wider audience, too, so that’s why I’m posting it here.
This is a bit of a rant by Skud, who used to work on Freebase, a large open-licensed data repository which imported data in bulk from a range of sources, including Wikipedia, Netflix, the Open Library Project, and many more. She’s had a lot of experience in this area, and learnt a lot about the weird complications of mass data imports.
They have a database. You have a database. Your fields are the same. Their API is easy to use and their license is compatible.
What if the fields aren’t quite equivalent? For instance, let’s say they have measurements in imperial and we use metric. We’ll need to have ways to convert them. That’s actually a really simple example. Import incompatibilities are more often at a semantic/ontological level. Growstuff has the idea of “crops” and “varieties” but what if the other database only has “plants” with no distinction? Or what if they have crops and varieties but draw the line somewhere slightly different to where we do? These sorts of incompatibilities are more common than not, and massively complicate any import effort.
Nothing against that other database – some of everyone’s data is bogus! But we need to check it. What “bogus” means will vary from place to place, but it might be spam entries, duplicate records, simple errors, or it might be cruft from their own broken imports. We need to look carefully at every import and make sure we’re skipping as much of this as possible. And this is largely a manual process, since what the bogosity will never be the same twice. You can do this by sampling, of course, but you still need to look at something on the order of a hundreds of records, and know what you’re looking for. Could you spot a mixed-up scientific name on a randomly chosen herb? I couldn’t.
Let’s say we want to import from a database of plant life that lists 10,000 edible plants and their nutritional content. Growstuff has 300 crops at present. We import everything! Now we have 9,700 pages with nothing but nutritional data. Nobody on Growstuff is using them, they have no pictures, they have no planting data, they have no discussions (except maybe spam comments that nobody cleans up because nobody notices). Our “newest crops” page, usually a source of interest, is now just a wasteland of grey placeholder images.
Should we have imported all 10,000 plants, or just the nutritional data of the 300 we already have? Or something in between? The answer is usually “something in between” – you might want that data if and only if you can get other partial data from other imports to make it more interesting.
The best way to do this is to import the 300 and make a note of the 9700. Then later, you can cross-correlate the notes you’ve made from various data imports and re-import those that have, say, at least 3 useful data sources and a picture. But that’s pretty complicated. (Also, see the discussion of repeated imports, below.)
Let’s assume that their data is licensed compatibly – that means CC-BY-SA or CC-BY in our case, since we’re CC-BY-SA and none of the other clauses (ND, NC) are compatible with us. (Ignoring CC-0 and public domain stuff for now – those don’t need attribution at all.)
So by importing, we have to credit them. Now we need some way to represent that in the database. If we do this at the object level, it’s fairly simple: each thing in the database (crop, etc) has many licensors, each of which includes a name for the work (eg. “Katie’s Plants”), a license (eg. CC-BY), a licensor name (eg. Katie Smith), and a URL to link to the original data.
Now we have to display them on the page. Where? Probably at the bottom somewhere: “Some information on this page came from: Katie’s Plants (that would be a link) – CC-BY Katie Smith; SuperPlantDB under CC-BY-SA SuperPlants Inc; etc.”
Now imagine that the data on those sites came from other sites. For instance, let’s say Katie’s Plants previously did an import from Freebase.com, and SuperPlantDB did one from Wikipedia. We not only need to credit Katie’s Plants and SuperPlantDB but also those places.
Some questions to consider:
Sure, we could just choose not to chain licenses, or to do it in some restricted way… but the moral high road here is to respect everyone’s license and attribution, and besides, if you only attribute some contributors, where do you decide to draw the line?
This is a subset of license chaining problems. Let’s say Growstuff (a commercial entity using CC-BY-SA) imports from Katie’s Plants (a non-profit entity using CC-BY-SA) which imports in turn imports from Hippie Herbs (a non-profit entity using CC-BY-NC – note the “non-commercial” clause).
Katie’s fine – she imports from Hippie Herbs’ data with impunity because she’s non-profit. She attributes them on her site, and Hippie Herbs is happy. She doesn’t have to use the same license as them because they don’t have a “SA” (Share Alike) clause.
Now Growstuff comes along and wants to import data from Katie’s Plants. Katie’s Plants is CC-BY which is compatible with Growstuff… but what about the data that originally came from Hippie Herbs? We’re commercial, so we’re not meant to use it.
But how do we tell what’s what? Katie probably doesn’t attribute HH at the level of individual bits of data, so we can’t extract just the ok-for-commercial-use bits.
Basically, if you believe in license chaining (and as I said, it’s definitely the moral high road to take, so I think we should) then you have to be constantly vigilant for the taint of NC-licensed data anywhere in the sprawling tree of ancestors to your data.
The simple case is fine for a green-field import with no existing data, which is described above. But let’s say we’re importing data into an area where we already have some contributions from Growstuff members.
Let’s say we decide to adjudicate. We now need to build an app to let people vote on which one is “correct” – probably best of three or something like that. Freebase did this (multiple times) and I was involved in some of it. We called them “data games” and had leaderboards for who’d voted the most. We couldn’t get enough throughput, though, and sometimes by the time something had been adjudicated, another community member had edited the field on our site, thus invalidating the whole thing. We ended up paying people in developing countries to churn through these votes for us (we used ODesk, but you could use Amazon’s Mechanical Turk or whatever). However, they needed training, and weren’t cheap – even after all the work of setting up the voting queue, there was still considerable expense.
This came up quite often with Freebase because sometimes they would import from “authoritative sources” who licensed their work specially to Freebase but didn’t generally have a CC license or an open community editing process. For instance, the time when I was talking to some people from the BBC, and one (an older dude) said, “If we gave you our programme data, we wouldn’t want anyone to edit it because we are the experts on our programmes.” This was pretty silly of course – another, younger BBC dude immediately turned to him and said “Ha ha ha, I’ve got two words for you: Doctor Who.” – but sadly these situations are common when you’re dealing with closed/non-community-based/”authoritative” data sources who don’t understand the power of crowdsourcing information.
But even when dealing with compatibly CC-licensed sources with open developer communities, there can still be some problems around the “authority” of the data and how it’s attributed.
Take the case where Katie’s Plants community have spent heaps of time editing their data and are very proud of it. We import it to Growstuff, then our community looks at it and decides that bits of it are wrong and change it.
Do we leave the license link to Katie’s Plants intact? Most likely yes, because our data has theirs in its DNA, so to speak. But what if we essentially deleted all the data from there? This might happen if, for example, we’d imported a picture from Wikimedia Commons then found that the picture was incorrect or inappropriate, so we blew it away. Now we should probably remove the license note. But how do you tell when data has been completely removed as opposed to modified or built upon?
In the Katie’s Plants example, what if Katie’s high quality medicinal plant information gets mixed up with ($DEITY forbid!) low-quality data from less experienced Growstuff members or from yet another import? What implications does this have for Katie’s site and their reputation? Under the license we’re allowed to mess it up because there is no “No Derivatives” (ND) clause, but socially/culturally they’ll be pretty unhappy if we do, and we can expect some backlash.
Great news! Katie got a government grant and some fantastic press coverage, and her database has expanded enormously. We want to re-run the import. But now consider this case:
When we first imported, we put it to adjudication and found that Growstuff’s data was better, so we went with that.
Now we re-import, and Katie’s data has changed:
So of course we put it through adjudication again. The correct answer is probably a union of the two sets.
Now, Katie’s database is growing fast, and so is Growstuff. We want to do a regular import from there – perhaps monthly. But somehow along the way, we’ve ended up with different ideas of tomato colour. Every month, their data is different to ours, and we have to keep re-adjudicating the same question: what colour/s are tomatoes? Boring. Our community is tired of playing the voting game, and/or it’s costing us money with our Mechanical Turk people.
So we decide to implement a check: if nothing’s changed on either side since the last adjudication, leave it. But now we have to implement change tracking, not just on Growstuff, but on Katie’s Plants as well. We need to keep a history of changes for every site we import. This is in addition to the infrastructure we’ve had to build to automatically run imports at regular time intervals.
Obviously we have an API for people to access our data under CC-BY-SA. But keep in mind the license-chaining effect: if anyone uses data from Growstuff, they will also be constrained by the licenses of all the data sources we import. We will need to make that license information available in the API alongside our data, and make sure all our API docs and related materials explain the necessity of license chaining.
Take a look at Freebase’s Attribution Policy. They use CC-BY, but because of attribution chaining, they can’t just say that – they need a whole page with a wizard to help people figure out how to attribute something on the site. It’s incomplete, too: Freebase decided that they would only require license chaining for “content” as opposed to “facts” (a complicated issue in itself) which means images Wikipedia-based descriptions. They don’t require chained license information for other data sources. This is dubious in terms of the legality and culture of how Creative Commons works – there’s no really firm guidelines on this, but in my opinion the most moral/ethical stance is to always chain your attributions, and Freebase has chosen otherwise. In the past, this has caused some concern from the owners of other data sources that were imported to Freebase. Even Wikipedians have complained that Freebase doesn’t enforce their Wikipedia attributions strongly enough. This sort of thing can lead to reputation problems, if not legal ones.
One final complication. Various courts have ruled that “facts” aren’t copyrightable. For instance, the fact that the crop “Corn” has the scientific name “Zea mays” can’t be copyrighted. Even if you have thousands of these facts all together, they can’t be copyrighted, because they’re not a “creative work”. They’re just a statement of fact.
This actually throws the whole idea of CC-licensing collections of data into doubt. And yet we have nothing better, so we do it anyway.
Some data projects have come up with various justifications for this. For instance, Freebase says that the arrangement of the facts is a creative work – that what’s CC-licensed is their schema. That’s pretty creative in itself! The thing is, none of this has really been tested. And so most open data projects have some kind of Terms of Service which explains what they think the CC-license is for and how it’s meant to be used. These generally say, “By accessing our data via our website or API, you agree to behave as if this CC license applied to it (even if there’s not a very strong legal basis for that outside this TOS).”
The original idea of CC licenses was to stop people having to write their own terms and conditions of use for their work, and standardise in such a way that people could easily re-use creative content. Yet for data projects, we end up having to make up our own TOS just to apply a CC license, and we’re back where we started – having to peer at a bunch of legalese and figure out what the hell it means.
Of course once you get into the complexities of license chaining described above, you now also have TOS chaining – if Growstuff uses Katie’s data under their TOS, and Katie uses Hippie Herbs’ under their TOS, is Growstuff now subject to Hippie Herbs’ TOS? No idea! I am not a lawyer! I don’t want to be one! I just want to make a website about growing food!
Importing data is hard! That doesn’t mean we shouldn’t do it, but we should go into it with an awareness of the potential potholes, and carefully weigh up whether importing something is the best choice for us at any given time.
Katies Plants, Hippie Herbs, and SuperPlantDB are all made-up examples. Any resemblance to actual open data projects is coincidental. Freebase, Wikimedia Commons, and the BBC are real, though.
